4.2 Маркировка гиперспектральных данных и формирование обучающей выборки
В данном разделе рассматривается процесс маркировки входных данных для обучения и построения качественных и устойчивых моделей. Для создания обученной модели в первую очередь необходим корректный ввод и маркировка основных классификационных показателей.
Маркировка данных для обучения может включать в себя как добавление основных классификационных показателей, так и дополнительных, содержащих второстепенную информацию. После выхода в меню проекта на левой боковой панели можно увидеть все исследуемые образцы в формате таблицы. В первую очередь добавляется дополнительная переменная или идентификатор (рисунок 32), содержащая информативные данных об образце (кнопка в нижней части страницы). При этом предварительно выбирается тип дополнительной переменной или идентификатора и указывается её наименование (рисунок 33) с последующим присвоением имени переменной или идентификатору каждого образца (рисунок 34, 35).
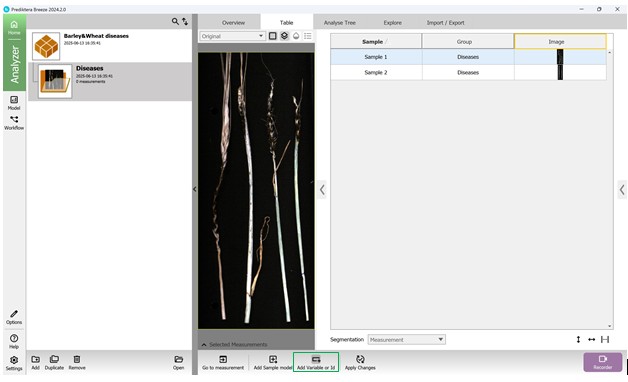
Рисунок 32 – Добавление дополнительной переменной или идентификатора
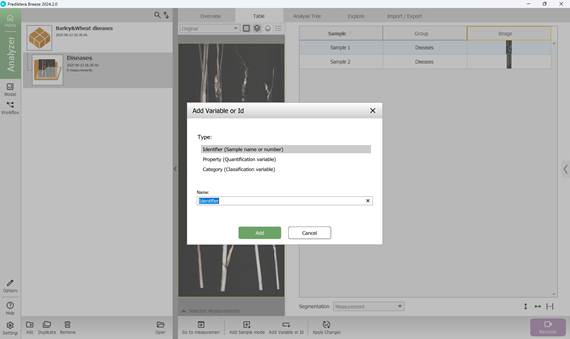
Рисунок 33 – Выбор типа дополнительной переменной или идентификатора и присвоение имени
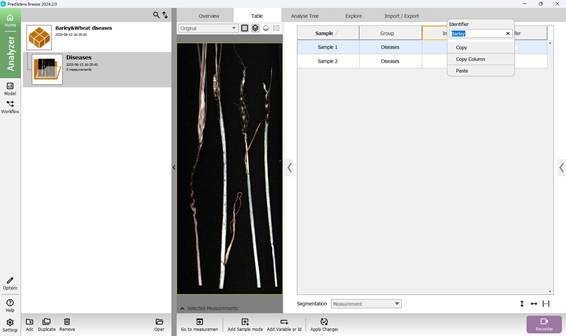
Рисунок 34 – Присвоение имени переменной или идентификатору каждого образца
Аналогичным способом добавляются основные классификационные переменные (категории) (рисунок 36, 37) с присвоением им известных значений (наименований заболеваний сельскохозяйственных культур) (рисунок 38).
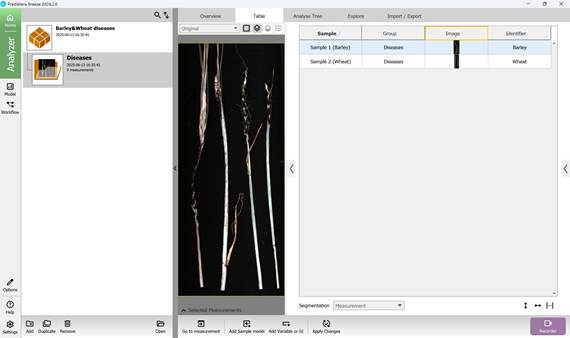
Рисунок 35 – Выборка образцов с присвоенными именами дополнительной переменной или идентификатора
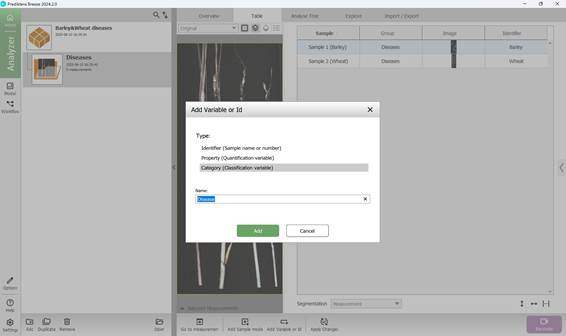
Рисунок 36 – Добавление классификационной переменной (категории)
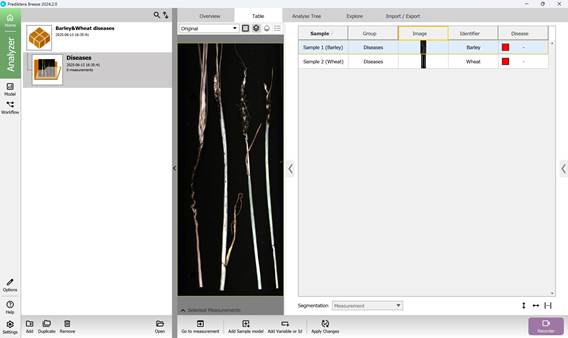
Рисунок 37 – Неизвестные классификационные переменные (категории) по умолчанию
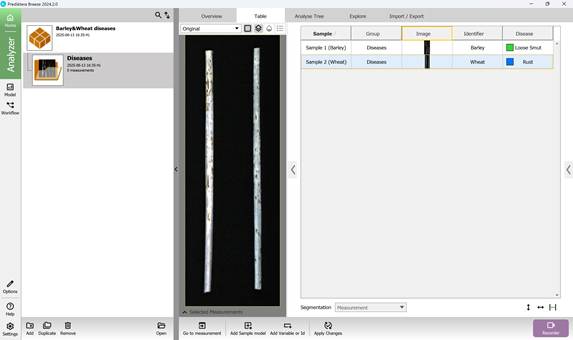
Рисунок 38 – Присвоение известных классификационных переменных (категорий)